
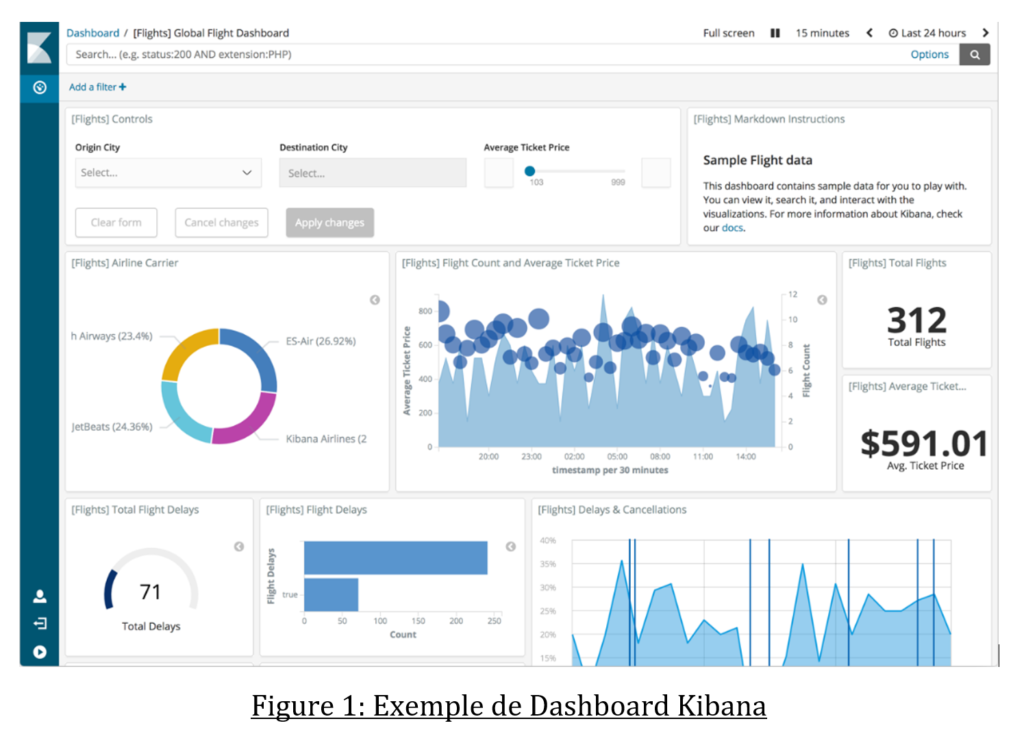
Afin de faciliter la supervision des flux synchrones et asynchrones, nous avons mis à l’épreuve un prototype composé de la stack ELK (Elasticsearch, Logstash et Kibana). Cette stack permet en effet d’effectuer des recherches dans une base de données NoSQL et d’afficher les résultats de manière visuelle. Ainsi, nous pouvons rassembler les logs de différentes applications et repérer les anomalies plus facilement. Voici la synthèse de ce test
L’objectif de notre prototype est la mise en place d’une solution de monitoring des différents flux synchrones et asynchrones.
Cet objectif repose sur trois exigences :
● Permettre de collecter les logs de plusieurs applications afin de corréler les traitements réalisés entre les différents micro-services.
● Fournir des Dashboard de supervision fonctionnelle/technique (ex : nombre de requêtes traitées dans la journée ratio en erreur /succès)
● Alerter les équipes en cas d’anomalie sur des composants/applications.
Pour cette étude nous avons choisi la stack ELK.
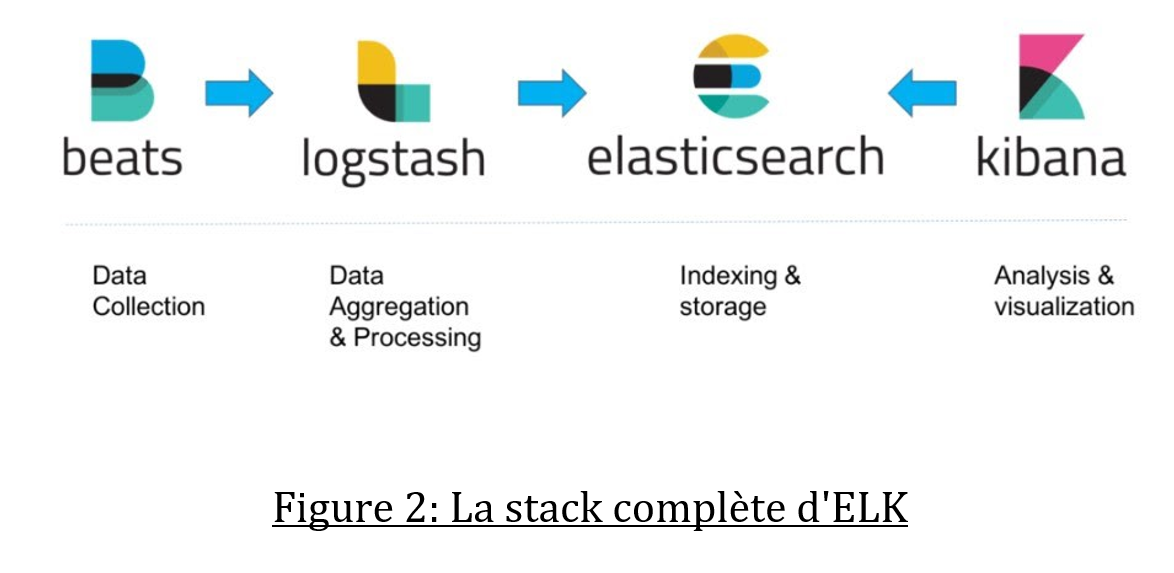
La stack ELK est formée de trois composants : Elasticsearch, Logstash et Kibana.
Elasticsearch est une base de données NoSQL, elle repose sur Lucene et permet de faire des recherches sur du texte.
Logstash est un composant qui va récupérer toutes les sources de données, les transformer et les renvoyer à Elasticsearch.
Enfin Kibana, c’est l’interface de visualisation qui permet de faire des recherches et qui peut afficher les résultats sous forme de graphiques (on parle alors de widgets). Kibana va permettre la création de tableau de bord visuel.
L’intérêt d’ELK est de pouvoir unifier tous les logs d’un système d’information pour faire le suivi de la consommation des services ou pour retracer une erreur de transaction. Les logs de chaque application (serveurs, micro-services, …) sont transférés à Logstash avec un agent Beats (comme filebeat).
Architecture de notre système d’information
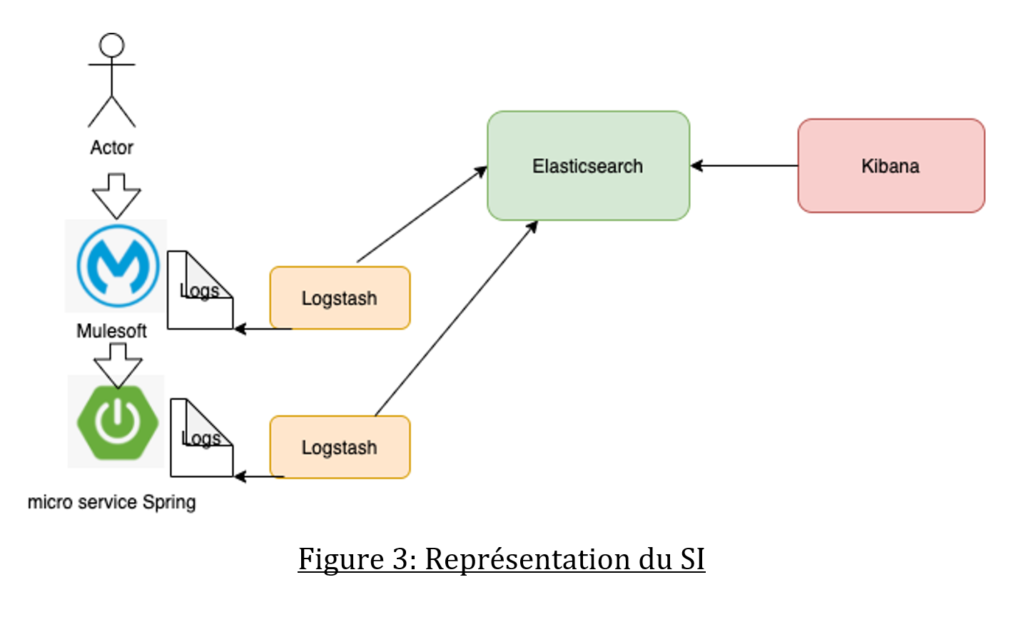
Pour le prototype nous avons installé un micro-service Spring tandis que l’API Manager MuleSoft expose l’API à un consommateur.
Nous avons pour chaque composant une instance de Logstash qui va récupérer les logs et les transférer à notre Elasticsearch.
Configuration de Logstash pour MuleSoft :

Logstash est un pipeline composé de trois parties :
● Input : Le répertoire où se trouvent les fichiers de Logs
● Filter : les règles pour filtrer (parser) les Logs
● Output : L’URL de notre instance Elasticsearch
Et la configuration Logstash pour notre micro-service :

Pour le suivi de bout en bout de la transaction nous transférons l’identifiant de corrélation de MuleSoft au micro-service Spring :

Ainsi nous pouvons rechercher notre transaction dans l’interface Kibana :
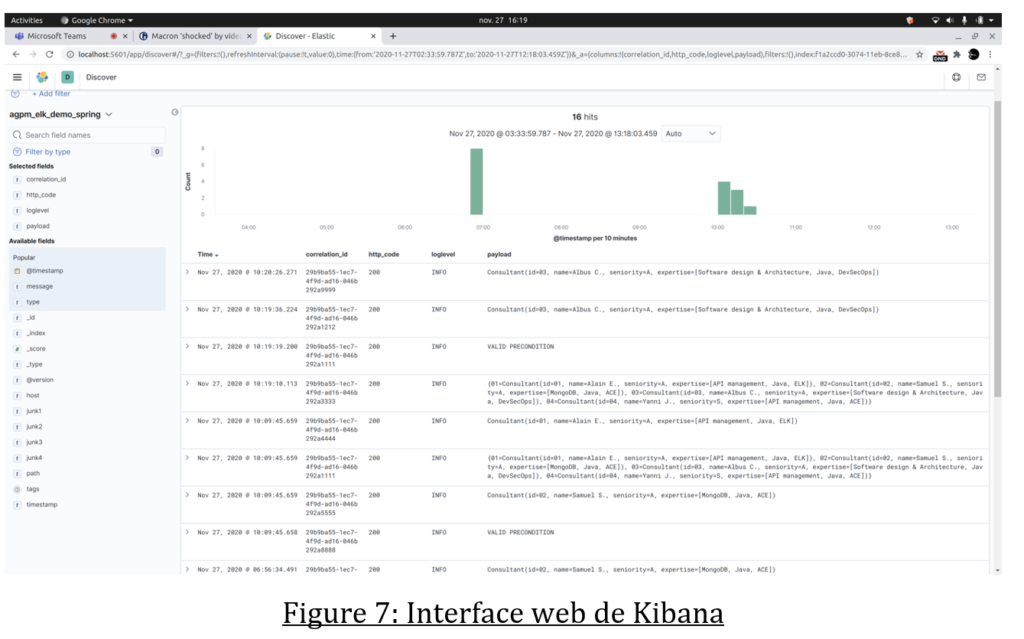
La mise en place d’une plateforme de monitoring nous permet de suivre les transactions de bout en bout. De plus avec les widgets de Kibana nous pouvons afficher un tableau de bord avec des indicateurs de performance ou de consommation.
Références
