

[chapo]Constat : les entreprises détiennent des sources de données nombreuses, diversifiées, ouvertes, disséminées selon les besoins des départements internes et de l’écosystème. Le poids de l’histoire, l’émergence du Big Data, la digitalisation et l’ouverture des systèmes d’information : tout concourt à la multiplication de ces sources, parfois redondantes. Lorsqu’il faut les rassembler à des fins d’analyse, par exemple, l’opération peut rapidement s’avérer chronophage.[/chapo]
Une solution à ce problème est la virtualisation des données (Data Virtualization). C’est une approche unifiant plusieurs sources dans une même couche d’abstraction, notamment sémantique, afin que les applications, les outils de génération de rapports et les utilisateurs finaux puissent accéder aux données sans se préoccuper de l’emplacement et de la structure d’origine de la source. Bienvenue dans l’univers de l’auto-discovery et de la donnée en self-service.
Des solutions existent pour mettre en place ce niveau d’abstraction. A partir de celles-ci, on crée des vues des tables/sources que l’on souhaite étudier, on regroupe différentes vues en une seule, même lorsque les tables proviennent de sources totalement différentes (par exemple, on peut combiner des données de bases MySQL, de fichiers CSV et d’Hadoop). On fournit un point d’accès unique aux données structurées et non structurées de l’entreprise.
Les solutions de Data Virtualization permettent aussi :
– d’unifier la sécurité des données pour l’ensemble de l’entreprise (et à l’extérieur) via la création de groupes (selon le type d’utilisateur),
– d’accroître l’agilité de l’équipe de développement lors du lancement de projets d’intégration de données,
– de découpler les consommateurs des données des structures physiques, pour modifier celles-ci tout en minimisant l’impact sur les utilisateurs finaux,
– de fournir des données opérationnelles en temps réel, traitées, nettoyées, pour répondre aux besoins les plus récents.
Pour comprendre comment cela fonctionne, nous avons choisi de poser un regard plus approfondi sur la solution Denodo, qui vient de créer sa filiale française et fait partie des leaders de ce marché.
Cette plateforme offre un accès unifié à une large gamme de services Big Data, Cloud, comme le provisionnement et la gouvernance. Parmi ses partenaires, on retrouve Cloudera et Hortonworks.
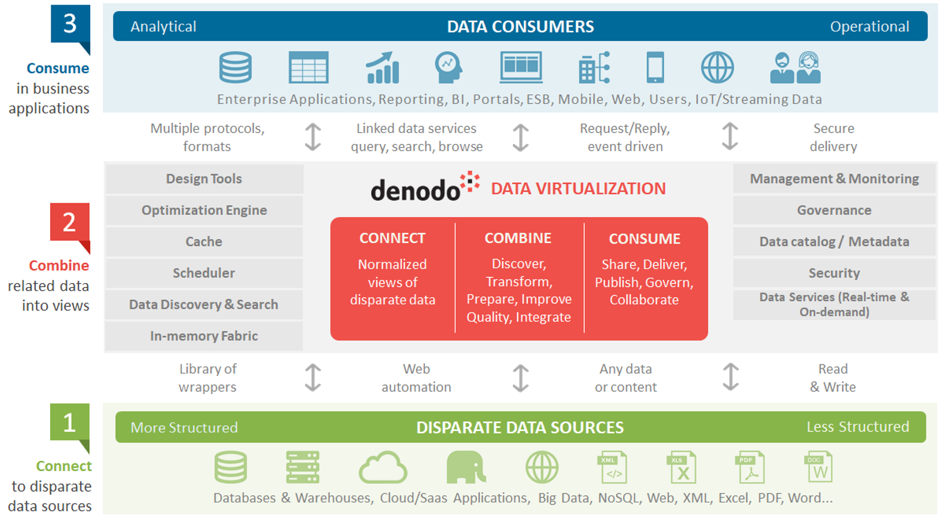
Le schéma ci-dessus permet de mieux appréhender la médiation que représente la solution de Denodo entre les sources de données et les consommateurs de ces sources. La plateforme requiert des équipes formées à son utilisation, capables d’opérer à un niveau fonctionnel (sémantique) et technique (connexion aux sources). Sur ce point, la solution est fournie avec une gamme de connecteurs tous gratuits.
On se trouve ainsi en face d’un produit qui peut se substituer à une solution de type ESB sur un pattern spécifique de Data Virtualization, dans la mesure où il offre des fonctions avancées dédiées à ce pattern et qui dépassent nettement ce qu’un ESB sait nativement offrir :
– possibilité de modéliser les données, la recherche globale et la gestion du cycle de vie des données,
– mise en cache intelligente pour améliorer les performances en temps réel et minimiser les flux de données,
– optimisation des requêtes, avec un langage dédié (mais propriétaire),
– sécurité fine avec définition des utilisateurs/rôles (ou leur importation à partir de LDAP/AD), restrictions d’accès finement structurées (jusqu’au niveau de la cellule de données), masquage des données et application de politiques de sécurité personnalisées,
– prise en charge d’analyses complexes en temps réel et intégration avec les principales plates-formes de calcul en mémoire et de Cloud.
A noter l’exposition d’API qui assure l’insertion de la plate-forme dans un écosystème plus large.
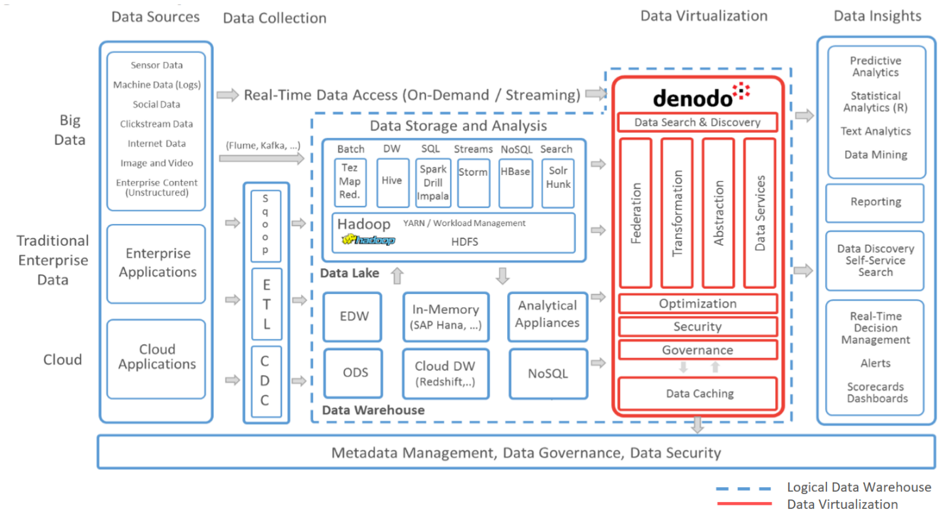
Précisément, cette solution n’est pas sans impact sur le plan de la gouvernance et de l’organisation des Centres de Compétences Big Data. Elle s’insère entre les sources de données (traitées et manipulées par les Data Engineers) et les consommateurs (dont font partie les Data Scientists) pour fluidifier la manipulation des données par ces derniers et simplifier la sécurité.
On assiste ainsi à une extension probable du rôle des Data Engineers, voire à une spécialisation de certains Data Engineers sur ce sujet spécifiquement, d’autant que la plate-forme offre des fonctionnalités assez avancées qui justifient de s’y plonger pleinement :
– en design-time : définition centralisée du glossaire métier avec lignée de données avancée, analyse d’impact des changements et recherche de catalogues,
– en run-time : suivi de performances de bout en bout pour détecter les goulots d’étranglement, traçabilité de l’ensemble des opérations…
En conclusion, la virtualisation de données bouleverse la manière d’utiliser et d’analyser des données en entreprise, en réduisant considérablement le temps dédié au transfert, au nettoyage et au traitement des données avant leur analyse.
Cette valeur ajoutée peut constituer un avantage fort pour les entreprises se décidant à l’utiliser, auquel il convient de se préparer tant sur le plan technologique que sur celui de l’organisation et des méthodes.
