

Les leaders et experts du marché envisagent pour la plupart des perspectives d’usages et des caractéristiques différentes du Data Catalog, ce qui rend toute tentative de définition unique périlleuse. Néanmoins la correspondance d’au moins deux types de fonctionnalités semble être une caractéristique commune à toutes les implémentations disponibles actuellement sur le marché.
Le premier concerne la collecte de métadonnées associées à l’usage envisagé d’une donnée dans un contexte spécifique, usage indépendant de toute forme d’implémentation (ex usage « Client » envisagé dans un contexte finance, marketing, solution, technologique …). Le second propose la collecte de métadonnées associées à l’usage d’une donnée dans son contexte d’implémentation (ex usage de l’implémentation « Client » dans le contexte d’un système de stockage de données opérationnel, application digitale, système transactionnel, système analytique…).
Métadonnée à l’usage envisagé par les métiers
Sur les 10 dernières années nous avons constaté une multiplication des technologies tournées autour du digital, que ce soit matériel (smartphone, fibre, …) ou logiciel (système d’exploitation, CRM, …). Cette évolution se constate aussi par les organisations qui adoptent de plus en plus ces nouvelles technologies, ce qui génère une multiplication de la donnée au sein des organisations.
Parmi toutes les innovations technologiques introduites sur le marché et qui exploitent l’information sur l’usage de la donnée ou la métadonnée, le Data Catalog propose d’associer celle issue d’un contexte technique (ex : usage par une implémentation de systèmes opérationnels, décisionnels, analytiques, AI, intégration de données, fichiers …) à celle issue d’un contexte métier (ex : usage par une exigence, discours, loi, texte réglementaire… ).
Ainsi, nous remarquons que l’utilisation de termes communs (ex : client, identifiant, …), que ce soit lié aux métiers, aux solutions ou aux technologies de l’entreprise, multiplie les incompréhensions et les mauvaises communications.

En effet, la notion de « Catalog » a longtemps accompagné des personnes chargées de manipuler la donnée associée à un processus ou au discours d’un langage utilisé dans l’entreprise, une donnée qui n’était pas nécessairement rattachée à un système. Elle était plutôt associée à une initiative (ou collaboration envisagée) sur un périmètre d’analyse ou à un/des domaine(s) métier(s) de l’organisation.
L’objectif de ce glossaire était de faciliter la communication entre toutes les parties prenantes d’une initiative.
C’est pourquoi la capture de différents types de métadonnées associées à un usage envisagé dans ces contextes est une nécessité.
Nous pouvons notamment parler des métadonnées descriptives qui permettent :
● De découvrir les données pour les nouvelles personnes qui entrent dans l’organisation,
● D’identifier les données pour des besoins précis quant à l’analyse et l’étude,
● De comprendre la signification de chaque donnée d’une table.
Métadonnée à l’usage d’une ou plusieurs implémentations
La notion de donnée est fréquemment associée à son implémentation dans une application ou classification propre à un ou plusieurs domaines de l’organisation (ex : catégories et types de produits, clients …).
Cette donnée dispose d’un descriptif de notions, termes, définition mais également de caractéristiques structurelles, syntaxiques et sémantiques ainsi que de valeurs autorisées propres à son usage dans différentes implémentations.
Ce descriptif de données de l’entreprise pouvait entre autres faire l’objet d’un inventaire de termes et de caractéristiques d’implémentation – métadonnées associées à une initiative spécifique – et souvent nommé dictionnaire de données.
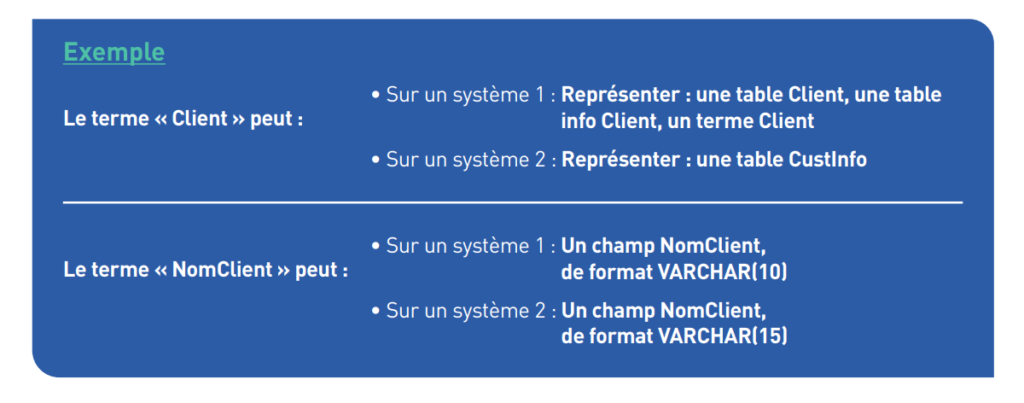
Dans ce cadre, nous pouvons notamment parler des métadonnées techniques, administratives ou encore de structure et bien d’autres qui permettent une utilisation multiple de la métadonnée :
● Comprendre les relations entre les familles de données d’un même domaine,
● Visualiser la structure logique de modèles de données multi-domaines,
● Avoir les types et les versions des informations des outils SI,
● Conserver les informations d’historisation des données stockées.
