

Ces dernières années, le domaine du Process Mining a émergé et ses techniques visent à traduire les données saisies pendant l’exécution du processus en informations exploitables.
Qu’est-ce que le Process Mining ? Quelles sont les données à utiliser pour faire du Process Mining ? Quelles sont les analyses possibles dans les outils de Process Mining ? L’article ci-dessous répondra à toutes ces questions.
Définition du Process Mining
Les systèmes d’information modernes nous permettent de suivre, souvent de manière très détaillée, l’exécution des processus (suites d’évènements) au sein des entreprises. Prenons par exemple la manutention des bagages dans les aéroports, les processus de fabrication des produits et des marchandises, ou les processus liés à la prestation de services, tous ces processus génèrent des traces de précieuses données sur les événements.
Ces données sont généralement stockées dans le système d’information d’une entreprise et décrivent l’exécution du processus en question.
Ces dernières années, le domaine du Process Mining a émergé, à la frontière entre le Data Mining (extraction de modèles et de connaissances à partir de données) et le Business Process Management (analyse de processus), et plus généralement entre la Data Science (science des données) et la Process Science (science des processus).
Les techniques de Process Mining visent à traduire les données saisies pendant l’exécution du processus en informations exploitables. À ce titre, trois principaux types d’analyse de Process Mining sont identifiés : la découverte de processus, le contrôle de conformité et l’amélioration des processus.
● Dans la découverte de processus, le but est d’identifier et d’établir un modèle de processus, c’est-à-dire une description comportementale formelle, qui décrit le processus tel que capturé par les données d’événements.
● Dans le cadre du contrôle de conformité, nous cherchons à évaluer dans quelle mesure les données relatives aux événements correspondent à un modèle de référence donné.
● Enfin, dans le cadre de l’amélioration des processus, l’objectif principal est d’améliorer la vision du processus, c’est-à-dire en améliorant les modèles de processus sur la base de faits dérivés des données d’événements.
Cet article se concentrera sur la découverte de processus et ses analyses.
Quelles données utiliser pour faire du Process Mining ?
Pour exécuter des algorithmes de Process Mining, il faut avoir en sa possession des données de type « event log », des journaux d’évènements, détaillant les différentes tâches réalisées dans le cadre du processus étudié, de préférence datées. Le format de données principalement utilisé est le format XES (eXtensible Event Stream), dérivé du format XML.
Il est possible de partir de fichiers CSV s’ils contiennent les variables suivantes :
● Trace : l’identifiant de la séquence/collection d’évènements (exemple : 1 pour la création du premier produit)
● Activité : le nom ou l’identifiant de l’évènement/la tâche réalisée (exemple : assemblage de deux parties d’un produit)
● Etat de l’activité : « commencée », « terminée », etc.
● Horodatage : la date et l’heure auxquelles a été effectuée l’activité
● Ressource : la ressource ayant réalisé l’activité (peut être une personne, un robot…)
Une grande diversité d’algorithmes et de visualisations
Dans les outils de Process Mining open-source, de nombreux traitements sont disponibles, allant de la description et des statistiques simples sur les différentes variables du journal aux visualisations des différents processus à l’aide d’algorithmes complexes.
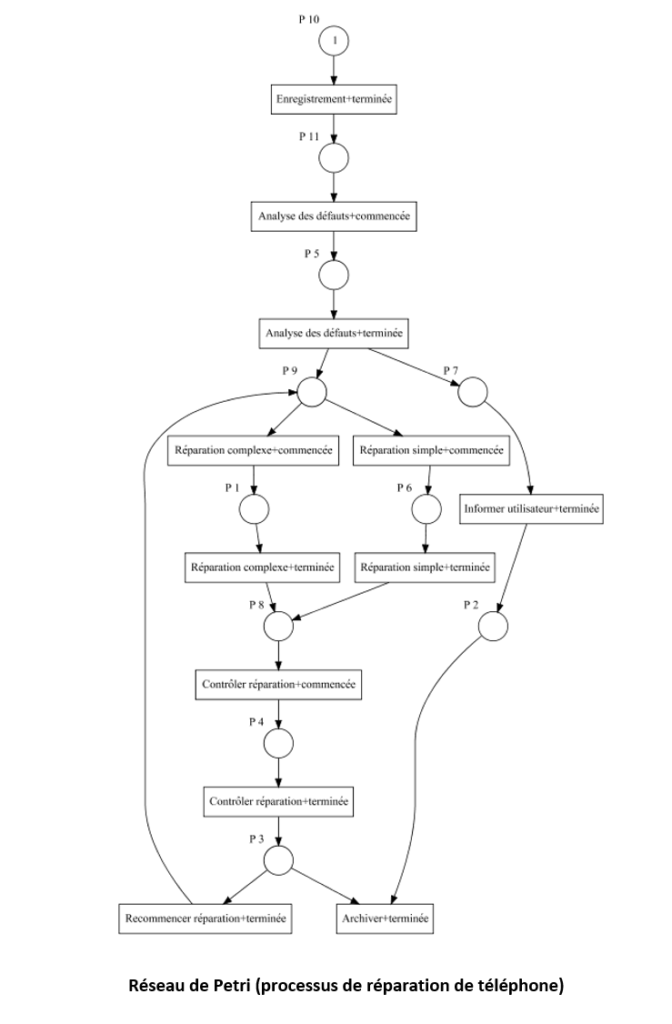
Une des analyses les plus utilisées en Process Mining est le réseau de Petri, permettant de modéliser un processus et ainsi déterminer les différents évènements (activités) et les transitions entre chacun de ceux-ci. Pour présenter rapidement, les évènements sont indiqués par des bulles, et les transitions par des flèches entre ces bulles.
Pour ce traitement classique, il existe plusieurs algorithmes permettant d’obtenir des visualisations différentes de ce réseau. Le résultat des algorithmes associés peut être modifié selon le paramétrage de ceux-ci, impliquant une certaine complexité pour les néophytes, même si les paramètres par défaut permettent déjà d’obtenir des résultats satisfaisants. Il est par exemple possible d’ignorer un certain pourcentage des données pour obtenir un modèle potentiellement plus simple et plus facilement lisible, ou encore de distinguer ou non deux mêmes activités avec des états différents.
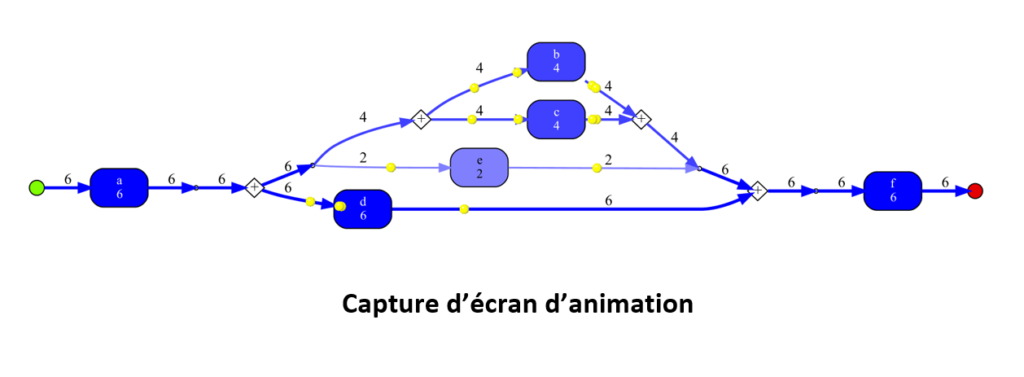
Une particularité de la découverte de processus en Process Mining est la création d’animations automatisées, une innovation par rapport aux visualisations plus classiques que l’on trouve généralement en Data Science tels que les graphiques statiques (histogrammes, courbes…). L’animation en exemple ci-dessous montre une image de l’animation d’un réseau de Petri, dans laquelle chaque jeton (en jaune) correspond au parcours d’un processus dans l’ordre chronologique, en tenant compte de l’heure et la date auxquelles chaque activité a été réalisée.
Le Process Mining, un domaine méconnu
Si le Process Mining peut être considéré comme un sous-ensemble de la Data Science, il n’en est pas moins très spécifique. En effet, de par les données qu’il utilise, à savoir des journaux d’évènements comportant plusieurs variables nécessaires à son application, ainsi que par ses visualisations, il peut être considéré comme une niche dans le domaine de l’analyse de données.
La découverte de processus en Process Mining permet de créer automatiquement des modèles de processus d’entreprise à partir des données générées par les ressources lors de la réalisation des différentes tâches. Ces analyses constituent une forte valeur ajoutée, permettant la bonne compréhension des processus en entreprise.
