

In recent years, the field of Process Mining has emerged. Its techniques aim to translate data captured during the execution of the process into usable information.
What is Process Mining? What data should be used for Process Mining? What are the possible analyses in Process Mining tools? The article below will answer all these questions.
Definition of Process Mining
Modern information systems allow us to track, often in a very detailed way, the execution of processes (sequences of events) within companies. Let’s take, for example, baggage handling at airports, products and goods manufacturing processes, or processes related to service delivery, all of which generate valuable event data traces.
This data is usually stored in a company’s information system and describes the execution of the process in question.
In recent years, the field of Process Mining has emerged, at the border between Data Mining (extraction of models and knowledge from data) and Business Process Management (process analysis), and more generally between Data Science and Process Science.
Process mining techniques aim to translate data captured during process execution into usable information. Three main types of process mining analysis are identified: process discovery, compliance monitoring, and process improvement.
● In process discovery, the goal is to identify and establish a process model, i.e., a formal behavioral description, that describes the process as captured by the event data.
● In the context of compliance monitoring, we seek to assess how well the event data matches a given reference model.
● Finally, in the context of process improvement, the main objective is to improve the process view, i.e., by improving process models based on facts derived from event data.
This article will focus on process discovery and its analysis.
Which data can be used for Process Mining?
To run Process Mining algorithms, you need to have in your possession event log data, detailing the different tasks performed in the studied process, preferably dated. The data format mainly used is the XES (eXtensible Event Stream) format, derived from the XML format.
It is possible to start from CSV files if they contain the following variables:
● Trace: the identifier of the sequence/collection of events (example: 1 for the creation of the first product)
● Activity: the name or identifier of the event/task performed (example: assembly of two parts of a product)
● Activity status: “started”, “completed”, etc.
● Timestamp: the date and time at which the activity was performed
● Resource: the resource that performed the activity (can be a person, a robot…)
A wide variety of algorithms and visualizations
In open-source process mining tools, a wide range of operations are available, from simple descriptions and statistics on the different variables of the log to visualizations of the different processes using complex algorithms.
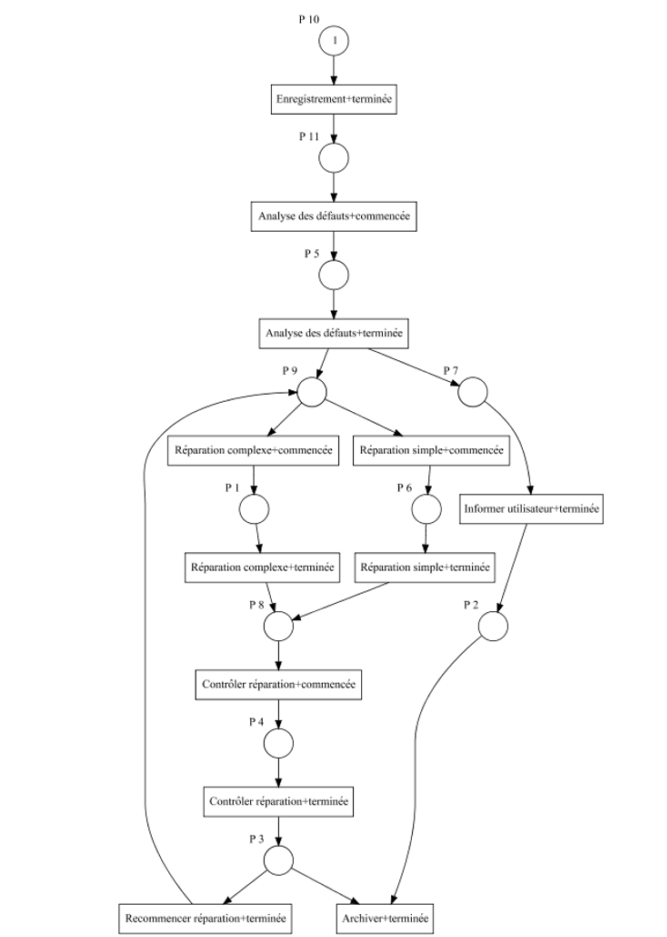
One of the most used analyses in Process Mining is the Petri net, allowing to model a process and to determine the different events (activities) and the transitions between them. Just to give a quick overview: events are indicated by bubbles, and transitions by arrows between these bubbles.
For this standard processing, several algorithms are allowing to obtain different visualizations of this network. The result of the associated algorithms can be modified according to their parameters, implying a certain complexity for neophytes, even if the default parameters already allow to obtain satisfactory results. It is for example possible to ignore a certain percentage of the data to obtain a potentially simpler and more easily readable model, or to distinguish or not two same activities with different states.
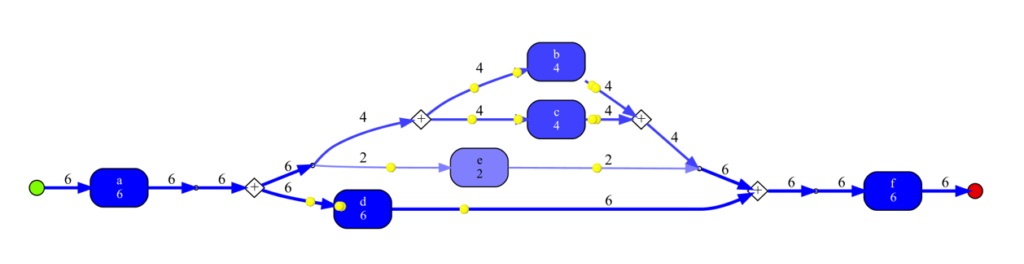
A particularity of process discovery in Process Mining is the creation of automated animations, which is an innovation compared to the more classical visualizations usually found in Data Science such as static graphs (histograms, curves…). The demo animation below shows an image of a Petri net animation, in which each token (in yellow) corresponds to the path of a process in chronological order, taking into account the time and date at which each activity was performed.
Process Mining, a little-known field
If Process Mining can be considered as a subset of Data Science, it is nonetheless very specific. Indeed, because of the data it uses, namely event logs containing several variables necessary to its application, as well as its visualizations, it can be considered as a niche in the field of data analysis.
The process discovery in Process Mining allows to automatically create business process models from the data generated by the resources during the execution of the different tasks. These analyses constitute a strong added value, allowing a good understanding of the processes in the company.
