

Le rôle de Data Engineer est apparu dans les années 2010. Il est perçu comme le complément technique du Data Scientist, ces deux rôles étaient complètement bien identifiés et segmentés : le Data Scientist s’occupe d’inventer les modèles statistiques reposant sur les données que le Data Engineer lui pourvoit.
Aujourd’hui, même si cela est encore le cas, la frontière entre le Data Engineer et le Data Scientist peut sembler floue. Il n’est pas rare qu’un Data Scientist, dans le cadre de sa mission, soit amené à exécuter des tâches de Data Engineering, pour préparer les données sur lesquelles il va travailler.
Du coup, quel est au juste le rôle du Data Engineer aujourd’hui ? Découvrez l’évolution de son rôle au fil du temps grâce à notre article.
Le rôle de Data Engineer est apparu au milieu des années 2010. Même si, selon certains, c’était un rôle qui existait déjà dans les chaînes de valorisation BI, il n’en reste pas moins que, lorsque nous avons notre livre blanc « Rôles et responsabilités dans la Data Science » fin 2013, il avait un peu disparu et était à peine identifié.
Il est revenu comme le complément technique du Data Scientist : le premier s’occupe d’inventer les modèles statistiques reposant sur les données que le Data Engineer lui pourvoit. C’est clair, net et précis, les rôles sont complètement segmentés.
S’ils le restent aujourd’hui, la frontière peut se montrer poreuse. Il n’est pas rare qu’un Data Scientist, dans le cadre de sa mission, soit amené à exécuter des tâches de Data Engineering, pour préparer les données sur lesquelles il va travailler.
L’inverse est moins vrai a priori, quoique… dans certaines entreprises, le Data Scientist est une compétence qui devient presque une commodité. Cela s’observe sur les salaires, qui sont parfois très éloignés des montants qu’on annonçait en 2012 pour le job « le plus sexy du vingt-et-unième siècle ». Ce phénomène s’observe notamment lorsque le Data Scientist n’est pas sollicité pour des activités complexes réclamant une connaissance mathématique et statistique approfondie, mais intervient sur des activités analytiques basiques. Ce n‘est pas la tendance majoritairement observée, mais il n’en reste pas moins que la profession de Data Scientist s’est banalisée.
Le balancier revient donc sur les activités techniques, qui reprennent une importance toute particulière dans le contexte de haute technicité qui entoure certains pipelines de données.
Les acteurs techniques de la CVD (Chaîne de Valorisation de la Donnée) sont au nombre de trois :
● Le Data Engineer,
● Le Data Architect
● Le DataOps.
Ces acteurs partagent nécessairement des préoccupations communes et un bagage parfois proche. Par exemple, le Data Engineer et le Data Architect vont travailler ensemble sur l’infrastructure Data de l’entreprise. On estime en cela que le rôle de Data Engineer est un préalable sérieux au rôle de Data Architect, car la maîtrise des technologies de pipeline est une expertise qui sera recherchée pour les deux rôles.
Le Data Engineer est ainsi la personne en charge de la mise en place des pipelines de donnée entre les différents systèmes applicatifs, afin d’apporter la bonne information au bon utilisateur au bon moment (l’utilisateur étant dans cette définition alternativement un Data Analyst ou un Data Scientist). C’est une définition assez proche de celle que l’on réserve habituellement pour les technologies de middleware et d’intégration, ce qui est normal car la collecte et l’intégration de données en sont un sous-domaine.
Nous verrons dans d’autres articles en quoi cette identité de concept amène aujourd’hui certaines entreprises à considérer la question de plateformes d’intégration complètes et mixtes, regroupant le monde du messaging et celui de la Data.
Le pipeline de données représente la collecte, le stockage et l’exploitation des données, mais le Data Engineering doit aussi être sensibilisé à des notions de gouvernance, de sécurité et connaître le contexte réglementaire, ce qui en fait un rôle assez complet, comme la majorité des rôles attachés à la donnée.
Notamment, sur la partie gouvernance de la donnée, il contribuera au lineage par lequel la traçabilité de la transformation de la donnée peut être établie, ce qui est indispensable compte tenu de la partie de la Chaîne de Valorisation de la Donnée sur lequel le Data Engineer intervient, avec des responsabilités claires dans la transformation de l’information.
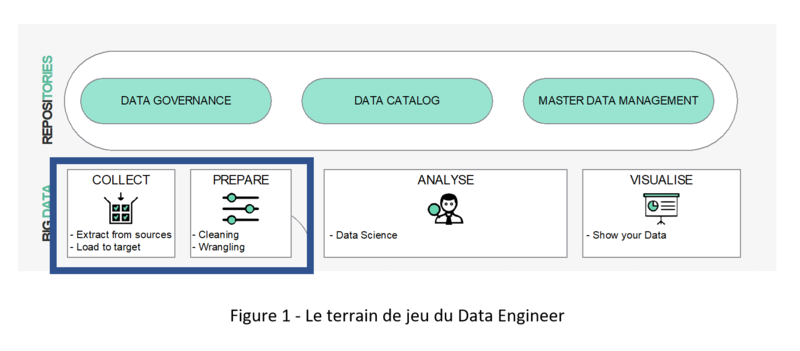
Au-delà, c’est le sujet de la qualité de la donnée qui apparaît centrale, puisque le Data Engineer peut être tenu responsable de présenter des données non fiables à ceux qui vont les exploiter. Même s’il ne peut être tenu responsable de tout, mécaniquement, cet aspect l’amènera à porter une attention particulière à la qualité tout au long de la chaîne de traitement. Et ce, au travers d’une diversité presque infinie de formats et avec des volumes massifs.
La diversité des technologies utilisées se vérifie lorsque l’entreprise fait le choix d’une Architecture ouverte, en mode best-of-breed. Lorsque l’entreprise porte son choix sur une plate-forme mono-éditeur ou simplement moins ouverte, le profil du Data Engineer change, devient moins technique, moins porté vers l’architecture et davantage porté vers les solutions.
Le travail du Data Engineer ne va pas uniquement porter sur la préparation des données en support du Data Scientist, chargé de la partie noble du travail et de faire parler les données. Une fois le travail du Data Scientist terminé, le Data Engineer va avoir la responsabilité de transformer en produit le travail du Data Scientist et donc de l’industrialiser :
● C’est aussi là qu’interviendra le Product-Owner Data en matière de coordination et de pilotage du travail par la valeur ou l’arbitrage valeur / complexité / risque.
● En l’absence de DataOps, rôle encore émergent, il est aussi un élément-clé de l’industrialisation et de l’automatisation de la plate-forme sur la Data à l’échelle de l’entreprise.
