

The role of Data Engineer appeared in the 2010s. It is seen as the technical complement of the Data Scientist, both roles were completely identified and segmented: the Data Scientist is in charge of inventing statistical models based on the data provided by the Data Engineer.
Today, even if this is still the case, the line between Data Engineer and Data Scientist can seem unclear. It is not uncommon for a Data Scientist, as part of his mission, to perform Data Engineering tasks to prepare the data he will work on. So what exactly is the role of the Data Engineer today? Discover the evolution of his role over time thanks to our article.
The role of Data Engineer emerged in the mid-2010s. Although some say it was a role that already existed in BI value chains, the reality is that when we wrote our white paper “Roles and Responsibilities in Data Science” in late 2013, it had somewhat disappeared and was barely identified.
He came back as the technical complement of the Data Scientist: the latter is in charge of inventing the statistical models based on the data that the Data Engineer provides. It’s clear, clean, and precise, the roles are completely segmented.
If they remain so today, the border can be porous. It is not uncommon for a Data Scientist, as part of his mission, to perform Data Engineering tasks, to prepare the data he will work on.
The opposite is less true at first sight, though. In some companies, being a Data Scientist is a skill that almost becomes a commodity. This can be seen in the salaries, which are sometimes far from the amounts that were announced in 2012 for the “sexiest job of the 21st century”. This phenomenon can be observed when the Data Scientist is not employed to perform complex activities requiring in-depth mathematical and statistical knowledge, but rather to perform basic analytical activities. This is not the main trend, but the fact remains that the Data Scientist profession is becoming common.
The focus then shifts back to technical activities, which are becoming particularly important in the highly technical context that surrounds certain data pipelines.
There are three technical players in the Data Value Chain:
● The Data Engineer,
● The Data Architect
● The DataOps.
These professionals necessarily share common concerns and sometimes a similar background. For example, the Data Engineer and the Data Architect will work together on the company’s data infrastructure. We believe that the Data Engineer role is a serious prerequisite for the Data Architect role because mastering pipeline technologies is an expertise that will be sought after for both roles.
The Data Engineer is thus the person in charge of setting up data pipelines between different application systems, in order to bring the right information to the right user at the right time (the user being in this definition alternatively a Data Analyst or a Data Scientist). This definition is quite close to the one usually reserved for middleware and integration technologies, which is understandable since data collection and integration constitute a sub-domain of this field.
We will see in other articles how this conceptual identity is leading some companies today to consider the issue of complete and mixed integration platforms, bringing together the world of messaging and that of Data.
The data pipeline represents the collection, storage, and exploitation of data, but the Data Engineer must also be aware of governance and security notions and be familiar with the regulatory context, which makes it a fairly complete role, like the majority of roles attached to data.
In particular, on the data governance part, he will contribute to the lineage by which the traceability of the data transformation can be established, which is essential considering the part of the Data Value Chain on which the Data Engineer operates, with clear responsibilities in the information transformation.
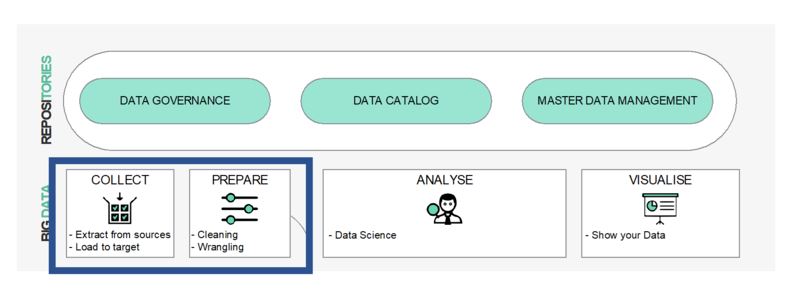
Beyond that, it is the subject of data quality that appears to be central, since the Data Engineer can be held responsible for presenting unreliable data to those who are going to process it. Even if he cannot be held responsible for everything, mechanically, this aspect will lead him to pay particular attention to quality throughout the processing chain. And this, through an almost infinite diversity of formats and with massive volumes.
The diversity of technologies used is confirmed when the company chooses an open architecture, in best-of-breed mode. When the company chooses a single-publisher platform or a less open one, the profile of the Data Engineer changes and becomes less technical, less architecture-oriented, and more solution-oriented.
The Data Engineer’s work will not only focus on data preparation to support the Data Scientist, who is in charge of the noble part of the work and of making data talk. Once the Data Scientist’s work is done, the Data Engineer will be responsible for transforming the Data Scientist’s work into a product and thus industrializing it:
● This is also where the Data Product-Owner will play a role in coordinating and steering the work by value or in value/complexity/risk arbitrage.
● In case there is no DataOps, which is still an emerging role, he is also a key element in the industrialization and automation of the Data platform at the enterprise level.
